1.10 眼在手上标定·GraspNet·LLM·6D 抓取
本文档需要配套对应视频观看,请联系助手获取视频(微信:ffcv1024)
- 学习本课程前需要学习前序课程
- 本节课需要切换到 Ubuntu 系统(非虚拟机),建议使用 Conda 创建虚拟 Python 环境
- 我的显卡:3060Ti
- 本节课代码:点击这里
1. 6D 抓取原理
我们已经了解 3D 抓取的基本流程,它的核心是标定找到相机到机械臂坐标系的转换关系,现在我们来处理 6D 抓取,6D 视觉抓取则是在 3D 位置信息的基础上,还要同时确定机械臂末端在绕各坐标轴的旋转姿态(
以 Episode 1 机械臂抓取系统为例:

我们可以看到这是眼在手上的场景(深度相机安装在机械臂末端),则分析可得抓取点在基座坐标下的位姿:
定义:
:抓取点在基座坐标系下的位姿(目标物体相对于基座),是我们要求的 :抓取点在相机坐标系下的位姿 ,可以通过深度学习检测网络 graspnet 得到 :相机在末端坐标系下的位姿(相机相对于末端) ,可以通过手眼标定得到 :末端在基座坐标系下的位姿(末端相对于基座) ,可以通过正运动学得到
所以
假设
夹爪相对于末端的位姿,一般厂家会直接提供,或者通过三点法、轨迹优化或视觉辅助等方法标定得到,即 TCP(Tool Center Point)标定。
所以新的末端在基座下的位姿(使夹爪位于抓取点):
所以主要需要解决以下问题:
- 使用深度学习检测网络 graspnet 求
- 使用手眼标定求
我们先处理第二点。
2. 眼在手上标定求
先复习一下《九、相机内参、相机标定、手眼标定原理、3D 抓取》 一课中介绍的手眼标定原理:
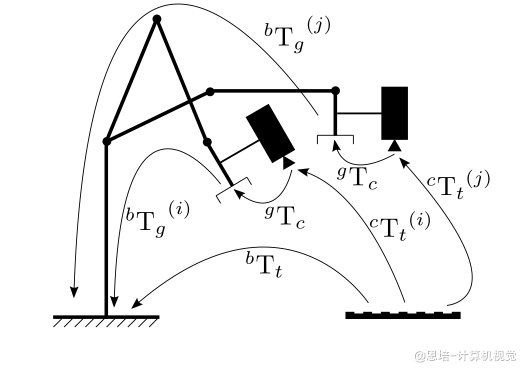
-
在眼在手上标定过程中,标定板和机械臂底座不动、夹爪和相机的相对位置不变,所以
和 是常量。对于第 次标定,两次不同位置的标定可得到 -
我们的目标是求解
: - 这是矩阵方程求解问题
- 可以将等式变换得到
的形式来求解(常见解法:Tsai–Lenz、Park–Martin、Dual Quaternion 最小二乘。)
-
我们的目标是消去中间的
,从而得到 的形式。
令:
,通过正运动学得到 ,通过 PnP 求解
则可得:
需要说明一下,上面的
- 相机坐标系到夹爪坐标系的变换矩阵
- 夹爪坐标系到基座坐标系的变换矩阵
对象主要是夹爪(gripper),换成末端(end)也是成立的,对应关系:
对应 对应
现在我们用此原理来求:
2.1 准备工作
| 步骤 | 配图 |
|---|---|
| 升级上位机版本:V 0.9.7 以上,并禁用状态更新(降低获取角度为 None 的概率) | 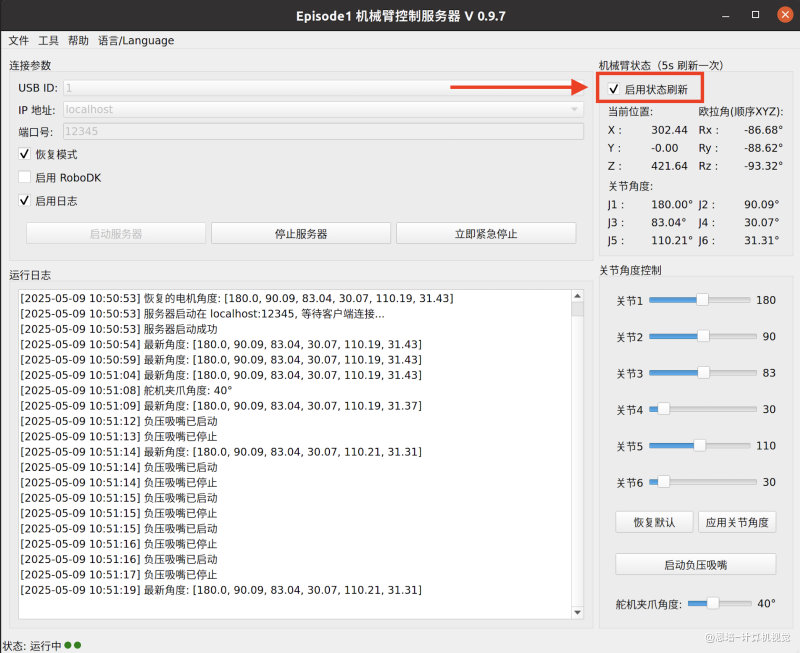 |
| 上位机启动机械臂,运动到默认位置 |  |
运行 python 1.generate_points.py prepare,机械臂会移动到准备位置 |
 |
| 安装 D435 及相机支架 |  |
2.2 预采样
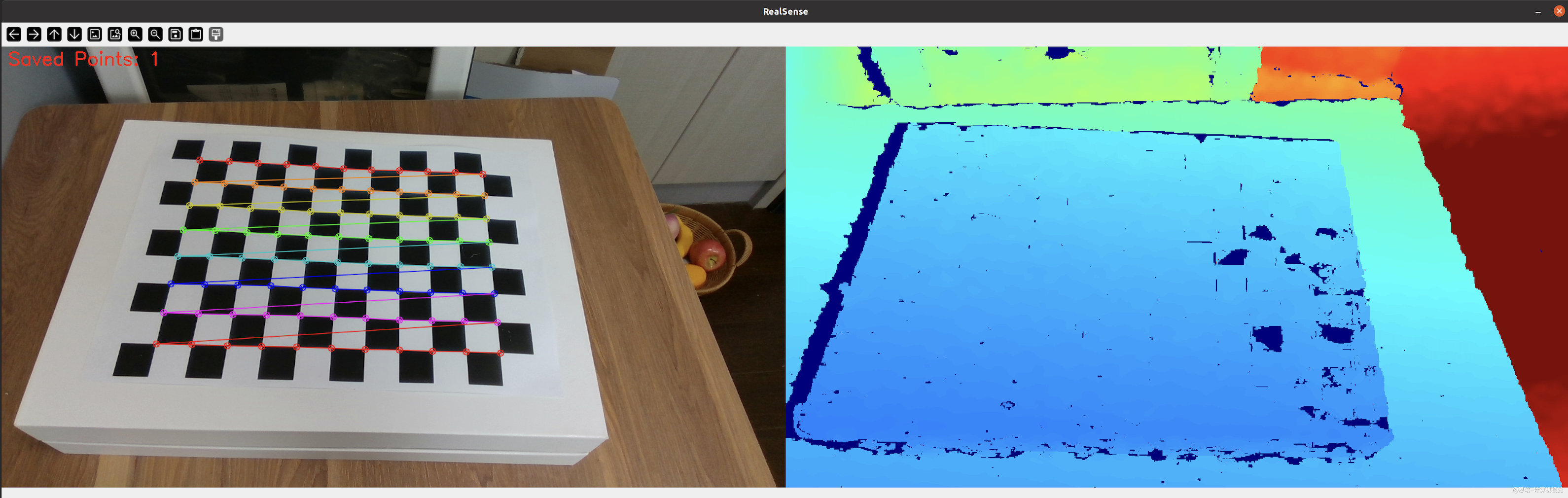
什么是预采样,为什么要做?
- 目的:标定要求在若干不同的机械臂姿态下,完整拍到棋盘格的所有角点;若角点缺失,该姿态的数据就得作废。
- 难点:你可以用示教器或上位机预设姿态,但实操中很难一次就保证角点全可见,往往要反复调姿,既费时又费劲。
- 优势:预采样让操作者直接拖拽机械臂,实时确认“这一姿态能否看全角点”。先筛掉无效姿态,再保存合格姿态,大幅缩短准备时间。
为什么预采样的数据不能直接拿来标定?
在拖拽过程中,减速器回隙(Episode 1 机械臂回隙介绍)与人为扰动无法避免,会降低标定精度。
正确做法是:
- 拖拽预采样——选出能完整看到角点的姿态;
- 记录这些姿态;
- 让机械臂自行运动到这些姿态并采集图像。
这样可消除回隙与手动误差的影响,保证标定精度。
预采样不是必须的,如果你的机械臂不支持拖拽示教,可以跳过本步骤,直接到正式采样。
-
体验 Episode 1 示教模式:
python 0.teach_mode.py prepare # 进入教学模式,记录机械臂运动轨迹 python 0.teach_mode.py replicate # 复现已记录的机械臂运动轨迹 -
棋盘格
- 下载课程用的棋盘格标定图 Checkerboard-A1-65mm-11x8, 在平板电脑等显示器上显示
- 不建议打印,经测试,打印出来的标定板标定结果很差(可能打印机打印精度原因,显示器像素点精度会更高一些)
- 如果不希望使用显示器,可以购买标准的棋盘格标定板
-
修改
config.yaml参数,改为自己棋盘格的数据# 棋盘格参数 checkerboard: pattern_size: [11, 8] # 内角点数量 [列数, 行数] square_size: 15.2 # 方格尺寸(毫米) -
运行
python 1.generate_points.py generate -
10S 后,机械臂将自由运动,需要你用手托住机械臂(或者让他人帮忙)
-
对准棋盘格,按空格键采样、S 键退出采样,采样结束后机械臂重新锁定,这时可以松开手
-
采样策略类似上一课相机标定(获取内参):
- 标定板质量比采样策略更重要!!!先优先解决高质量标定板
- 20 张以上,棋盘格占画面不同位置、距离、倾斜角;
- 保证旋转和平移要大
- 光照均匀、不反光,角点清晰;
- 分辨率保持相机原始大小。
- 需要关闭自动对焦
下面是我的拍摄策略:
# 棋盘格朝向 相机视角† 距离 建议张数 1 横放
(Landscape,长边水平)正对 近 1 2 中 1 3 远 1 4 横放 左偏 ≈15° yaw 近 1 5 中 1 6 远 1 7 横放 右偏 ≈15° yaw 近 1 8 中 1 9 远 1 10 横放 俯视 ≈20° pitch↓ 近 1 11 中 1 12 仰视 ≈20° pitch↑ 近 1 13 中 1 -
采样结束,会在
calibration_images目录下生成degrees_list.npy文件,保存的就是各个采样点对应机械臂的 6 个关节的角度。 -
1.generate_points.py代码比较简单,它是一个机械臂标定点采集程序,使用 RealSense 相机和 Episode 机械臂,通过检测棋盘格角点并记录机械臂角度,为后续标定提供标定点位角度数据。
2.3 正式采样
运行 python 2.generate_images_and_T.py,它会:
- 根据之前保存的角度列表自动移动机械臂
- 捕获棋盘格图像并计算相应的变换矩阵
- 保存变换矩阵和棋盘格图片
因为 Episode 1 回隙的影响,有时会出现预采样时棋盘格可以检测到角点,在正式采样没有。此时需要重新预采样。
如果你用的不是 Episode 1 机械臂,请修改代码自行保存变换矩阵和棋盘格图片。
2.4 标定
运行 3.calibrate.py 启动标定程序,它会:
- 加载正式采样的变换矩阵和棋盘格图片
- 根据棋盘格图片 PnP 求解
- 重投影误差评估
- 使用标定算法:HORAUD、TSAI、PARK 求解
,并保存为 T_camera2end.yaml
这是我的某次标定结果,供参考:
T_camera2end:
- - -0.9954378428969486
- 0.09004544369758916
- 0.03154867664380184
- 20.5282409825746
- - -0.09041386952457586
- -0.9958494520498034
- -0.01044993060744222
- 71.11403533817372
- - 0.030476763710470325
- -0.01325469431604081
- 0.9994475873963198
- 11.064690942584472
- - 0.0
- 0.0
- 0.0
- 1.0
2.5 测试
我们需要测试标定的
-
安装负压吸盘,注意安装时不要碰到相机,否则需要重新标定:

-
抓取测试运行命令:
# 测试抓取
python 4.test_gripper.py
# 核心代码
# ───── 坐标转换 ─────
# 构建相机坐标系下的齐次坐标
P_camera = np.ones(4)
P_camera[0:3] = center
# 转换到工具末端坐标系
P_end = T_camera2end @ P_camera
# 转换到机器人基座坐标系
P_base = T_end2base @ P_end
在抓取时,用的公式是
- 正常误差范围:由于存在标定误差以及 Episode1 J1 底座减速器的回隙(详见:回隙说明),抓取位置与几何中心的偏差在 ±10mm 范围内属于正常现象。
- 标定检查建议:若偏差超过 10mm,可能是以下问题:
- 深度相机数据有问题,尤其是二手的深度相机
- 标定的
有问题 - 光照问题
- Aruco 标定板安装不规范
- Episode 底座侧边紧固螺丝未紧固,回隙过大
- 减少回隙建议:如需尽可能减小减速器回隙影响,欢迎联系助手购买 J1 谐波减速器升级套件(需要更换第一个关节电机、减速器、法兰、相应螺钉等,底座外壳等不需要更换)。
3. 6D 抓取
3.1 Graspnet 环境配置
GraspNet 是一个大规模、用于机器人抓取研究的三维数据集和基准测试平台,支持无序环境中多物体的 6D 姿态估计与抓取检测任务。

- 我们使用的是它开源的 GraspNet Baseline 版本,推荐使用更成熟的付费版 AnyGrasp。
- 它的环境配置参考步骤:参考这里
3.2 Graspnet 测试
-
紧固二指夹爪螺丝

-
卸掉负压吸盘夹爪,换成二指夹爪

-
桌子上放一些测试抓取的物体,比如香蕉,运行
python 1.verify_grasp.py,代码相关参数:# 初始化调整参数 self.extra_degree = 83 # 单位度 self.extra_height = 100 # 单位mm self.filter_max_angle = 30 # 单位度 self.filter_min_height = 10 # 单位mm self.select_threshold = 20 # 单位个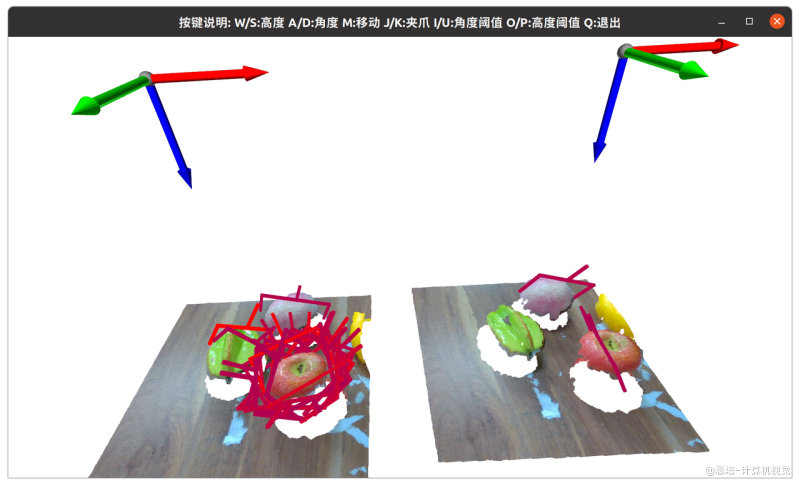
- 左侧为 Graspnet 识别的可抓取位姿,已经通过
self.select_threshold过滤置信度较高的前 20 个 - 右侧为筛选后的可抓取位姿:
- 通过
self.filter_max_angle = 30筛选摘取角度,太斜的过滤掉了 - 通过
self.filter_min_height = 10筛选抓取点高度(距离桌面),这里是要求大于 10mm
- 通过
- 当右侧有可抓取位姿,在窗口上按"M" 键,机械臂即可运行到抓取点:
- IK 必须有解
- 通过
self.extra_degree = 83设置了夹爪先抓角度 - 通过
self.extra_height = 100设置了夹爪距离抓点的高度,防止直接撞到
- 按键事件:
- W/S: 调整
self.extra_height - A/D: 调整
self.extra_degree - M: 调用机械臂 API 运动,会遍历可抓取位置,直到找到有解的可抓取位置
- J/K: 打开关闭夹爪
- I/U: 调整
self.filter_max_angle - O/P:调整
self.filter_min_heigh - Q:退出,进行下一次采样
- W/S: 调整
- 我们运行测试程序的目标就是通过调整这几个参数,提高抓取成功率。
- 左侧为 Graspnet 识别的可抓取位姿,已经通过
3.3 6D 抓取程序
3.3.1 简介
为了避免和 graspnet 的环境冲突(两者 Python 版本也不一样),我们需要用 conda 新建一个虚拟环境,我的环境信息:
- Conda 环境名称:episode_env
- Python 3.8.20
- NVIDIA GeForce RTX 3060 Ti
- 各种库版本信息(pip 导出)
也就是我们最终的 6D 抓取分为两部分:
episode_env环境下的对话识别部分2.demo_VLM_grasp.py:- 负责解析自然语言,路由到对应函数处理
- 调用 LLM、VLM 处理文字、图片数据,生成检测框等数据
- 保存为中转数据文件
graspnet_env环境下的抓取部分3.demo_VLM_handler.py:- 循环检测中转数据文件是否存在
- 负责最终的抓取
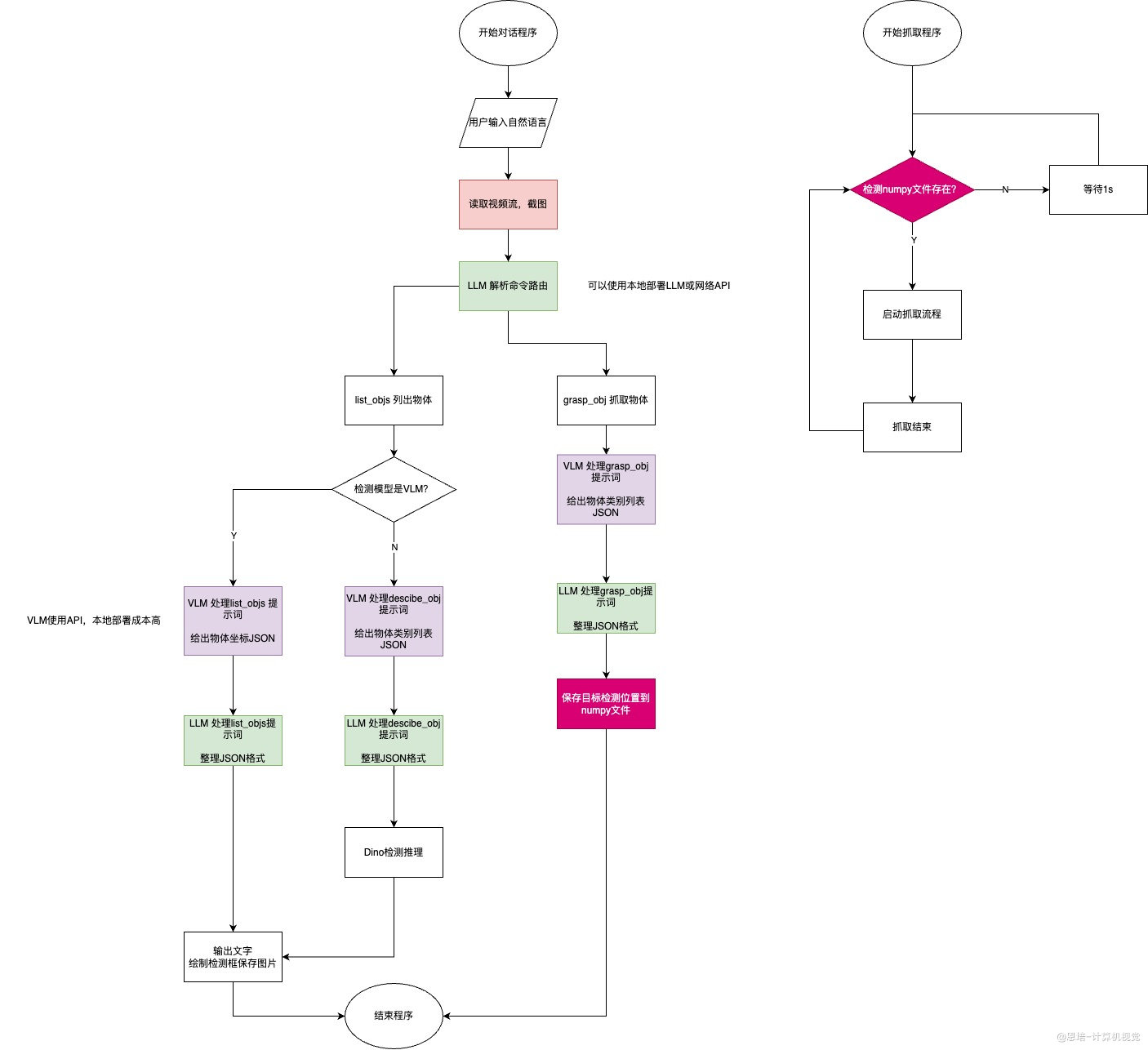
对话图片识别程序主要可以解析两类自然语言:
| 示例 | 动作 | 图片 |
|---|---|---|
| 桌子上有哪些东西?有什么?桌子上有什么等类似咨询问题 | 列出所有存在的物体,并打上检测框 | 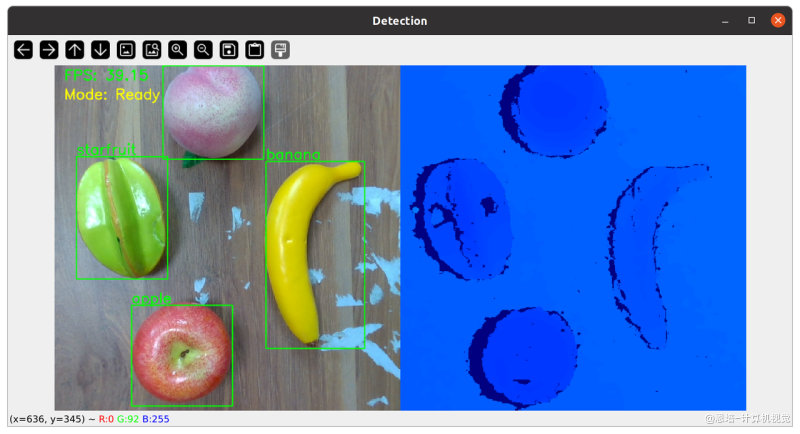 |
| 把香蕉放进盒子里等类似抓取动作 | 找出需要抓取的物品,打上检测框,并生成中转数据文件给抓取程序使用 | 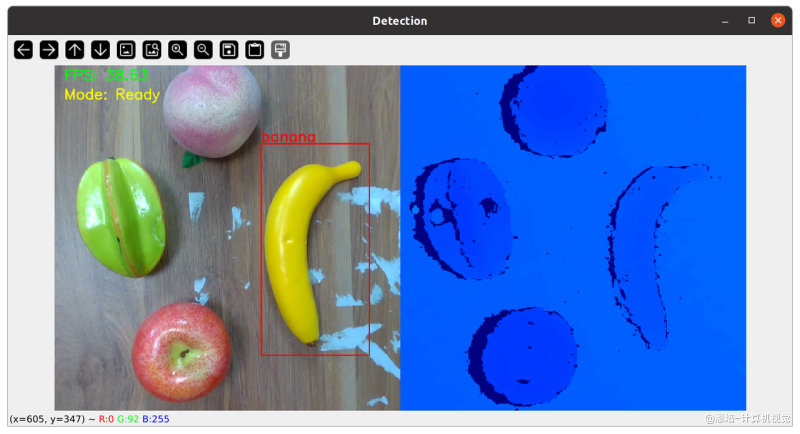 |
使用的大模型主要有
- LLM(大语言模型,图中绿色):负责解析路由、JSON 字符串标准化,可以选择
- 本地 Ollama 部署:如
qwen2.5:7b - 网络 API 调用:如
qwen-max、deepseek-v3
- 本地 Ollama 部署:如
- VLM(视觉大模型,多模态模型,图中紫色):主要负责检测目标,可以选择:
- 网络 API 调用:
qwen2.5-vl-72b-instruct
- 网络 API 调用:
- 检测模型还可以选择本地部署的:
grounding-dino-base
3.3.2 API 模式
网络 API 模式,也就是我们所有的 LLM、VLM 都使用网络 API 调用。
-
首先需要申请
API Key,比如阿里云申请如今 LLM 等大模型,基本调用协议都支持 OpenAI 模式,基本上只需要换一下
base_url即可,如下面是阿里云的调用方式:client = OpenAI( api_key=self.API_KEY, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", ) # 向大模型发起请求 completion = client.chat.completions.create( model=self.API_LLM_MODEL, messages=[ { "role": "user", "content": [ { "type": "text", "text": content } ] }, ] ) # 解析大模型返回结果 result = completion.choices[0].message.content.strip() -
然后再终端输入环境变量:
export DASHSCOPE_API_KEY="your-api-key"2.demo_VLM_grasp.py代码会获取这个环境变量:# API密钥配置,从环境变量获取 self.API_KEY = os.getenv("DASHSCOPE_API_KEY") if not self.API_KEY: raise ValueError("请设置环境变量 DASHSCOPE_API_KEY") -
修改代码:
# LLM类型选择:本地使用ollama,API使用阿里云 self.LLM_TYPE = ["LOCAL","API"][0] # 本地ollama模型配置 self.LOCAL_OLLAMA_MODEL = "qwen2.5:7b" # API LLM模型配置 self.API_LLM_MODEL = ["qwen-max","deepseek-v3"][1] # VLM模型配置 # 参考文档:https://bailian.console.aliyun.com/?tab=doc#/doc/?type=model&url=https%3A%2F%2Fhelp.aliyun.com%2Fdocument_detail%2F2845871.html&renderType=iframe # 由于多模态模型对硬件要求较高,直接使用API self.API_VLM_MODEL = "qwen2.5-vl-72b-instruct" # 检测模型配置,可根据需要在此处修改 self.DETECTION_MODEL = [self.API_VLM_MODEL,'grounding-dino-base'][0] -
测试运行
python 2.demo_VLM_grasp.py
3.3.3 LLM 本地部署
由于多模态模型对硬件要求非常高,VLM 我们就直接使用 API,但是 LLM 可以使用本地部署,我们使用 ollama。
-
安装 ollama
# 下载 curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz # 解压 sudo tar -C /usr -xzf ollama-linux-amd64.tgz # 启动 ollama serve -
使用的时候新开一个终端即可,如果希望自动后台运行,参考下文
# 添加用户、用户组 sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama sudo usermod -a -G ollama $(whoami) # 创建服务文件 `/etc/systemd/system/ollama.service`,内容如下 [Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=ollama Group=ollama Restart=always RestartSec=3 Environment="PATH=$PATH" [Install] WantedBy=multi-user.target -
各种服务命令
#重启 sudo systemctl restart ollama #停止 sudo systemctl stop ollama #状态 sudo systemctl status ollama #日志 journalctl -u ollama.service -f\n -
下载模型、运行模型
我的显卡是 3060Ti,选择测试的 LLM 是
qwen2.5:7b,如果希望测试其他模型,点击这里# 下载模型 ollama pull qwen2.5:7b # 命令行运行模型 ollama run qwen2.5:7b # Python API调用模型:https://github.com/ollama/ollama-python from ollama import chat from ollama import ChatResponse response: ChatResponse = chat(model='llama3.2', messages=[ { 'role': 'user', 'content': 'Why is the sky blue?', }, ]) print(response['message']['content']) # 输出消息 print(response.message.content) -
修改代码
# LLM类型选择:本地使用ollama,API使用阿里云 self.LLM_TYPE = ["LOCAL","API"][1] # 本地ollama模型配置 self.LOCAL_OLLAMA_MODEL = "qwen2.5:7b" # API LLM模型配置 self.API_LLM_MODEL = ["qwen-max","deepseek-v3"][1] # VLM模型配置 # 参考文档:https://bailian.console.aliyun.com/?tab=doc#/doc/?type=model&url=https%3A%2F%2Fhelp.aliyun.com%2Fdocument_detail%2F2845871.html&renderType=iframe # 由于多模态模型对硬件要求较高,直接使用API self.API_VLM_MODEL = "qwen2.5-vl-72b-instruct" # 检测模型配置,可根据需要在此处修改 self.DETECTION_MODEL = [self.API_VLM_MODEL,'grounding-dino-base'][0] -
测试运行
python 2.demo_VLM_grasp.py
3.3.4 抓取部分
graspnet_env 环境下的抓取部分代码 3.demo_VLM_handler.py,它的功能基本和 1.verify_grasp.py 一致,不过是自动化的:
- 循环检测中转数据文件是否存在
- 使用
graspnet推理出可抓取位姿 - 调用机械臂 API 抓取
- 放到固定位置
- 删除中转数据文件,继续下一次循环
在前面 1.verify_grasp.py 测试抓取时确定的参数,也需要同步到这里,尤其是 self.extra_height:
# 初始化调整参数
self.extra_degree = 83 # 单位度
self.extra_height = 10 # 单位mm
self.filter_max_angle = 30 # 单位度
self.filter_min_height = 10 # 单位mm
self.select_threshold = 20 # 单位个
本套课程到这里就结束了,感谢大家支持,希望以后有缘再见!