2.1 课程导引
同学们大家好!我们即将开启《实战 VLA 具身智能》的学习之旅。在正式开始实战之前,让我们先梳理一下核心概念和技术脉络,明确我们课程的目标和方向。
1. 具身智能(Embodied Intelligence)
具身智能代表了人工智能的终极形态——能够通过物理身体与真实世界直接交互的智能系统。其核心特征包括:
- 物理交互:拥有机器人身体,能在真实世界中移动和精细操作
- 感知-行动循环:通过多模态传感器感知环境,实时做出相应的物理响应
- 环境适应:能够适应复杂多变的真实环境,处理不确定性
- 持续学习:通过与环境的交互不断学习,优化行为策略
这是我们对未来机器人的终极期待,也是每一位技术人为之奋斗的目标。
实现具身智能的技术路径
为了实现这个宏伟目标,学术界和工业界探索出了多种技术路径:
| 技术路径 | 核心优势 | 主要挑战 | 典型应用场景 |
|---|---|---|---|
| VLA | 统一多模态,直观易懂 | 数据需求量大 | 通用机器人 |
| 强化学习 | 自主探索,无需标注 | 样本效率低 | 游戏、仿真 |
| 模仿学习 | 学习效率高,快速上手 | 依赖专家数据 | 特定技能学习 |
| 世界模型 | 样本效率高,可预测 | 建模复杂度高 | 规划类任务 |
| 神经符号 | 可解释性强,逻辑清晰 | 知识获取困难 | 推理类任务 |
技术融合的新趋势
近年来,混合架构正成为主流趋势,代表性组合包括:
- VLA + 强化学习:结合语言理解与自主优化
- 世界模型 + 模仿学习:高效建模与专家知识结合
- 符号推理 + 神经网络:逻辑推理与模式识别融合
成功的具身智能系统往往不依赖单一技术路径,而是根据应用场景选择最适合的技术组合。
VLA 的市场前景
作为最有前景的技术路径之一,VLA 正成为各大企业重点布局的核心技术。从猎聘网的搜索结果可以看出,VLA 相关岗位需求正在快速增长:
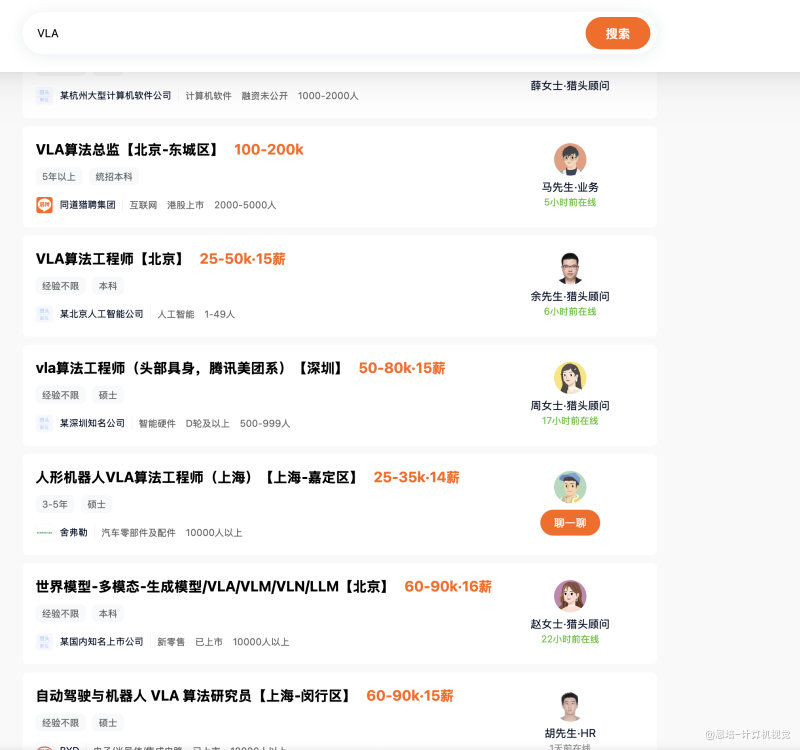
这也是我们选择 VLA 作为课程重点的重要原因——它既是技术前沿,也是市场热点。
2. VLA(Vision-Language-Action)深度解析
什么是 VLA?
VLA 模型是一种革命性的多模态 AI 架构,实现了三大核心能力的统一:
- Vision(视觉):处理 RGB 图像、深度图像、视频流等多种视觉信息
- Language(语言):理解自然语言指令,生成任务相关的文本反馈
- Action(动作):输出精确的机器人控制指令(关节角度、力矩等)
VLA 与具身智能的关系
VLA 是实现具身智能的重要技术路径,具体体现在:
- 技术实现层面:提供了完整的"感知 → 理解 → 行动"技术框架
- 能力整合层面:将三大核心能力统一在单一模型中,避免了模块间的信息损失
- 应用场景层面:让机器人能够接受自然语言指令并在真实环境中精确执行
示例场景:用户说"请把桌上的红色杯子拿给我"
- Vision:识别桌面环境,定位红色杯子
- Language:理解"拿给我"的语义和意图
- Action:规划并执行抓取 → 移动 → 递交的动作序列
主流 VLA 模型生态
目前活跃的 VLA 模型包括:
- ACT (Action Chunking Transformer):基于 Transformer 的动作预测
- Diffusion Policy:使用扩散模型生成连续动作
- π0 (Pi-Zero):零样本泛化的通用机器人模型
- Groot:大规模预训练的具身智能模型
- OpenVLA:开源的视觉-语言-动作统一框架
这个生态正在快速发展,新的模型和方法层出不穷。
3. 遥操作数据采集:VLA 训练的必要环节
为什么需要遥操作设备?
与传统深度学习模型(如 YOLO 目标检测)可以直接使用现有数据集不同,VLA 模型的训练面临着独特的数据挑战。让我们通过实际设备来理解:
| 执行机器人(从臂) | 遥操作设备(主臂) | 数据采集过程 |
|---|---|---|
 |
 |
 |
1. 数据稀缺性的根本挑战
现实世界数据极度匮乏
-
缺乏大规模数据集:
- 计算机视觉有 ImageNet(1400 万张图片)
- 自然语言处理有 CommonCrawl(数百 TB 文本)
- 机器人操作数据?几乎没有现成的大规模数据集!
-
任务多样性要求:每个具体任务都需要专门的训练数据
-
环境复杂性:真实世界的物理交互数据无法自动生成
高质量标注的严格要求
- 精确的动作标签:需要毫米级的位置精度、度级的角度精度
- 时序对应关系:视觉、语言、动作三个模态必须精确同步
2. 遥操作的独特价值
人类专家知识的有效注入
人类操作员 → 遥操作设备 → 机器人执行 → 数据记录
↑ ↓
丰富经验 完整的感知-行动轨迹
- 复杂推理能力:人类擅长空间推理和物理常识应用
- 实时适应性:面对意外情况能够灵活调整策略
- 任务理解能力:能够准确理解自然语言指令的深层意图
完整感知-行动循环的构建
- 视觉感知:操作员观察到的场景 → 模型的视觉输入
- 语言理解:操作员理解的任务指令 → 模型的语言输入
- 动作执行:操作员的精确控制 → 模型的动作输出
3. 其他数据采集方式的根本局限
纯仿真数据的问题
仿真数据的致命缺陷: • Sim2Real Gap:仿真与现实的巨大鸿沟 • 物理建模局限:摩擦、弹性、变形等复杂现象难以精确建模 • 视觉真实感不足:光照、材质、纹理与真实世界差异巨大
自主探索学习的困难
强化学习自主探索的瓶颈: • 样本效率极低:简单任务可能需要数百万次尝试 • 安全性风险:可能损坏昂贵的机器人设备或环境 • 探索效率低:在高维连续动作空间中难以发现有效策略
传统编程方法的限制
手工编程方法的问题: • 泛化能力差:仅适用于特定场景,环境稍有变化就失效 • 开发成本高:每个新任务都需要重新编程实现 • 鲁棒性不足:对感知误差和环境扰动极其敏感
4. 遥操作数据采集的完整流程
标准数据采集 Pipeline
1. 任务设计 → 2. 遥操作执行 → 3. 数据记录 → 4. 数据处理
↓ ↓ ↓ ↓
场景设置 人类操作员 多模态数据 清洗标注
语言指令 实时控制 (视觉+动作) 数据增强
采集的具体数据内容
- 视觉数据:RGB 图像、深度图像、相机内外参数
- 语言数据:任务描述、中间指令、完成状态标志
- 动作数据:关节角度、末端执行器位姿、抓取力度
- 环境信息:物体位置、场景布局、物理属性参数
课程目标与学习路径
通过本课程,你将:
- 快速上手 VLA 的核心概念和工程实现方法
- 动手搭建完整的遥操作数据采集系统
- 亲自训练自己的 VLA 模型
- 实际部署 VLA 模型到真实机器人系统
让我们一起踏上这段激动人心的具身智能探索之旅!